
TechLetters Insights. Pseudonymisation - the exciting element of modern data protection

Pseudonymisation is a technical and organisational measure and a data protection measure under the GDPR. It is a risk-reduction measure that minimizes the likelihood and impact of data protection breaches. It allows for controlled re-identification through stored additional information (secret information). Unlike anonymisation, which irreversibly removes the ability to link data to an individual, pseudonymisation retains the possibility of re-identification. The EU Data Protection Board released a dedicated opinion about it. The technique is a common need in many applications including in healthcare, finance, government processing, and more.
According to GDPR, pseudonymisation is: “the processing of personal data in such a manner that the personal data can no longer be attributed to a specific data subject without the use of additional information, provided that such additional information is kept separately and is subject to technical and organisational measures to ensure that the personal data are not attributed to an identified or identifiable natural person.” The desired effect of pseudonymisation is to control the attribution of personal data to specific data subjects by denying this ability to some persons or parties.
The use of pseudonymisation may also help demonstrate that a Privacy by Design process is implemented within the organisation.
When pseudonymisation is effective
Pseudonymisation mitigates the risk of confidentiality breaches (when databases are stolen, for example), but also more subtle privacy attacks like linkage attacks (linking data with external datasets to re-identify individuals) and, in some cases, membership inference (determining whether an individual’s data is included in a dataset).
Pseudonymisation mitigates confidentiality risks by replacing direct identifiers with pseudonyms or other transformations. It reduces the impact of data breaches when additional information is securely separated. It enables compliance with GDPR principles of data minimisation, purpose limitation, and confidentiality. Pseudonymisation protects data during processing, ensuring analysis without direct identification.
When pseudonymisation is insufficient
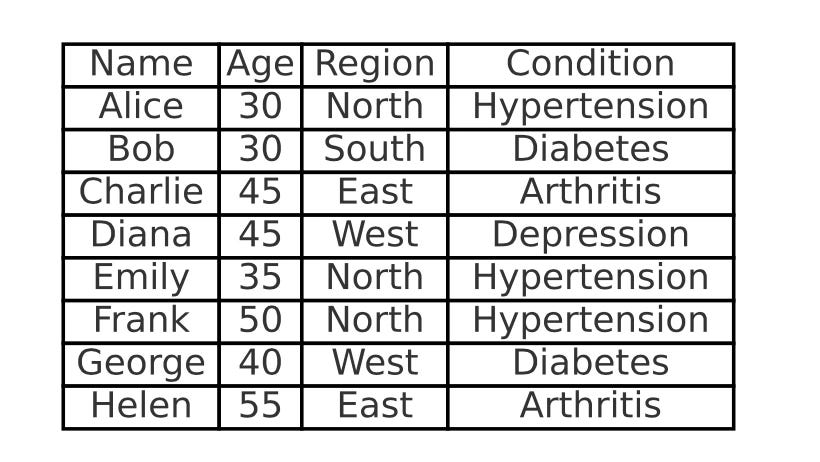
Pseudonymisation might be insufficient for certain types of data that enable the identification of quasi-identifiers. Quasi-identifiers are combinations of attributes, such as age, gender, marital status, profession, or income, that can reveal information about an individual's identity when processed together. If these attributes are known or correlated with external data, they can allow attribution of pseudonymised data to individuals without reversing the pseudonymisationtransformation. Mitigation measures include removing or modifying quasi-identifiers, for example via generalisation or randomisation. In the table below we may identify that the combination of (Age,Region) is unique - it uniquely identifies the name of the patient. Therefore replacing the name with a pseudonym would be insufficient.
There are plenty of other quirks about quasi-identifiers, but it's better to keep this discussion for anonymisation, not pseudonymisation (which need not guarantee anonymisation).
Common failures
Pseudonymisation does not prevent re-identification when quasi-identifiers are retained without adequate modification. It cannot ensure security if additional information (e.g., keys, lookup tables) is poorly managed or accessible. It is insufficient for high-risk data such as sensitive categories without complementary safeguards. Pseudonymisation also fails in adversarial environments where attackers possess auxiliary data or high computational resources (when the method was deployed badly).
Using weak cryptographic algorithms or low-entropy secrets makes pseudonymisation vulnerable to brute-force attacks. Storing pseudonymisation secrets alongside pseudonymised data or failing to restrict access to them is a bad practice. Not accounting for the possibility of external datasets that could enable linkage and re-identification increases risks. For example, external companies, or the government, may possess detailed information about the individual. If they obtain a pseudonymised data without this awareness, the pseudonymisation may be broken.
Attacks on pseudonymisation schemes
Breaking pseudonymisation schemes is the reversal of pseudonymisation, leaking of secret information, or more subtle risks like inference and linkage attacks, as well as reversing transformations. Linkage attacks involve correlating pseudonymised data with external datasets to identify individuals, while membership inference determines if specific individuals are included in a dataset. One breaking measure targets naive pseudonymisation methods.
For example, if an unkeyed hash function is used, attackers may generate a full candidate set based on all possible values (e.g., all IP addresses, MAC addresses, national IDs, or passport numbers) if the value space is limited. Generating a lookup table for all IPv4 addresses (2^32) requires only 128 GB of storage, making it computationally and technically feasible for attackers.
Sometimes, a custom-crafted solution is necessary rather than relying on a generic drop-in function.
Fortunately, today the risk of breaking a basic cryptographic building block is negligible so this risk may be assumed to be very low or even non-existent. That said, the actual design or application of a cryptographic scheme or protocol must be done with care. Sometimes algorithmic weaknesses in cryptographic algorithms are also unrelated to the robustness of pseudonymisation. For example even though numerous vulnerabilities of the MD5 hash functions are identified, a pseudonymisation scheme designed to use MD5 may still remain robust and fine. It's an example - don't use MD5 anyway. Some new techniques are also worth considering.
Important considerations
Two classes of replacement procedures are commonly applied as pseudonymising transformations: cryptographic algorithms and lookup tables.
If pseudonymisation is implemented to protect data released or transferred to another organization, or published, it is important to evaluate whether this method will continue to be safe for future releases. Certain circumstances may pose risks when multiple releases of different datasets compromise the effectiveness of pseudonymisation. Therefore, a thorough assessment of cumulative risks over time is crucial for maintaining its effectiveness.
If pseudonymisation is circumvented or reversed in any way, it loses its effectiveness. Pseudonymised data, which can be linked to an individual using additional information, is still considered personal data under the GDPR. Any compromise of the separation or security of this additional information allows for re-identification, making the protective mechanism ineffective and exposing the data to risks similar to those involved in processing non-pseudonymised data.
Example schemes:
One-way functions, including HMACs and specialized hash functions (e.g., Argon2). For example, an HMAC can use salted and peppered SHA-256 with a 256-bit key. Reversal would be impossible without the key. Common pitfall: using unkeyed hash function.
Symmetric encryption algorithms with strong keys for reversible pseudonymisation when needed. Common pitfall: hard-coding the encryption key in programs or scripts that applies pseudonymisation.
Keep in mind that lookup tables must be securely stored and access-controlled to maintain mappings. It’s also important to deploy technical measures such as network segmentation, secure APIs, hardware security modules (to store secret information), and rate-limiting mechanisms (to rule out brute forcing). Recommendation: do not store such keys in Github
Summary
Pseudonymisation is among the most interesting and important aspects of privacy and data protection engineering. It warrants careful consideration of the use case, good design, proper deployment, and monitoring. It's actually among the most exciting things in data protection, and the GDPR in fact.
Ps. Looking for a privacy architect, engineer, a DPO, or a consultant? Contact me at me@lukaszolejnik.com